Memory and registers
Pre requisites: previous posts.
Today we’ll be looking at memory and registers. You might not understand what those terms mean right now but that’s fine, by the end you should have a reasonable understanding of what they are and why they’re important.
This isn’t directly related to reverse engineering, but is necessary to grasp to understand a lot of what you see when reversing. This is by no means a complete guide and more will be explained in future posts, but it serves as a starting point.
Memory and registers both solve a similar problem. When you run the code you’ve written, whether compiled, interpreted or assembled, it will need to store data during exectuion. Everything from constant strings to variables to temporary values required for the current instruction need to be stored somewhere non persistent (i.e. non permanent) and easily accessible.
Taking a step back and looking at your computer as a whole, it consists of a number of components many of which you’ll likely be aware of. Most of the processing of applications takes place within the central processing unit, the CPU. Your CPU will have a speed measured likely in gigahertz - which is in the order of billions of cycles per second. The rest of the computer isn’t nearly as quick, your random access memory (RAM) for example could be running at half the speed of your CPU, and that’s before considering the distance between the components.
This might suggest a situation where the CPU is bottlenecked by the rest of the system, but this is where registers come in! Registers allow for a small amount of data storage and are built directly into the CPU. The reason they’re small is because they’re expensive and take up precious CPU space, but due to them being built directly into the CPU, they’re incredibly fast and can typically be accessed within one or two CPU cycles.
Let’s go back to part of the assembly from the previous post:
mov rax, 1
mov rdi, 1
mov rsi, msg
mov rdx, 13
syscall
The syntax for the mov instruction is mov [dest] [src], where [dest] is the destination for the data and [src] is the source. The instruction moves data from the source to the destination. In the above assembly, values are being moved into rax, rdi, rsi and rdx. This looks incredibly cryptic at first, until you realise that all these letters signify different registers within the CPU.
As register space comes at a premium, values are moved into registers when they’re going to be imminently used. In this case the four assembly instructions are parameters for a syscall that is called immediately afterwards.
To break down the name, let’s first look at rax. This is a 64 bit register, which means it can hold 64 bits of data. How do we know that though? It’s because of the r. eax refers to the same register but instead is just 32 bit, ax is the same register but 16 bits, and ah and al specify the upper and lower bytes of ax respectively.
This means if you modify eax, it will also modify rax and vice versa, and for 32 bit operating systems rax doesn’t exist.
These all operate on the same register, but on different bits of the register depending on how many bits you need. With AL and AH in particular you’re able to split a register into segments that can be used separately.
MEMORY MANAGEMENT
Now that we have an understanding of how registers work, we can take a look at memory management. When a program is run the contents is loaded into RAM, which is a type of memory that’s still faster to access than SSD or hard drives but relatively slow. For reference, RAM has roughly 10-20x longer access speeds than memory (this link is for much older CPUs but the ratios still roughly hold).
When loaded into memory, programs are broken into several segments which we’ll go into more detail about, but broadly:
- .text holds the actual instructions being executed
- .data holds initialised data
- .rodata holds initialised read-only data (think constants etc)
- .bss holds uninitialised data
- The heap holds dynamically allocated memory (in C, this would be data that is created through malloc)
- The stack holds local dynamically allocated memory and consists of stack frames
The CPU gives various “flags” to every segment of memory, which determines what can and can’t be done with them. .text and .rodata are usually non writeable for example, so the CPU will refuse to write to those segments as once loaded in they should remain the same. Every segment except .text is non executable, which means that the CPU will refuse to execute any instructions outside of the .text segment.
This is to prevent attacks that involve either changing instructions in the .text segment, or executing instructions outside of it. In the past the stack used to be executable and you were able to put instructions on the stack and redirect the instruction pointer to it to execute them.
The .data segment - which holds initialised memory - contains things like static and global variables. This is still writeable because those values can change throughout the exectuion of the program but the values are all initialised at the start of the program whilst memory is being allocated.
Whilst the program is starting the uninitilised memory segment, .bss, is set to 0, and it contains all static and global variables that are either not initialised or initialised to 0. There’s not a huge amount of difference between .data and .bss when it comes to reverse engineering, but it’s good to be aware of both of them.
When you define literals and constants, they go into .rodata (which is kind of a part of .data). The difference between .rodata and .data is that .rodata is read only as it only holds values that don’t change. Once .rodata is initialised, the CPU won’t allow for the values to be changed. When you for example, write printf("Hello world");, the “Hello world” part is a string literal and held in .rodata as it doesn’t change during the execution of a program. When opening code up in a hex editor you may see a big chunk of strings grouped together in one place, the reason for this is because they are all kept in the same place (i.e. the same memory segment).
The heap and stack are both incredibly interesting as they’re dynamically allocated during execution. Every other section has a fixed size at runtime but the stack and heap can shrink and grow during execution.
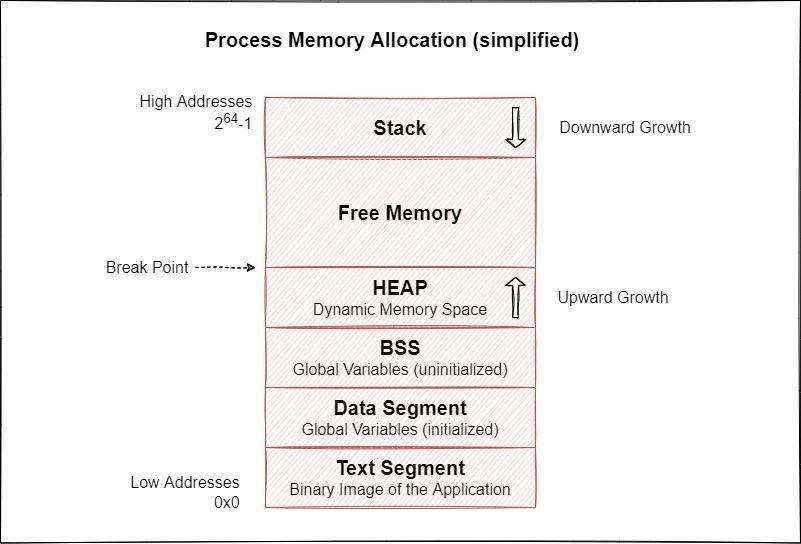
As per the above diagram, the stack starts at the highest memory addresses (0xFFFFFFFF) and the heap begins at the end of .bss, the stack grows down and the heap grows up.
The heap contains memory dynamically allocated by the programmer, for example by using malloc in C. The programmer will be responsible for freeing the memory once it’s no longer being used - if they don’t this can cause something called a memory leak where the continuously grows until the program runs out of memory and eventually crashes.
The stack follows what’s known as a first in last out model, meaning the first data added (pushed) to the stack is the last data data to the removed (popped) from the stack. As an example, let’s assume we have an empty stack, we push the values [1, 2, 3] -> the stack now consists of [1, 2, 3]. We then pop one value and add [4, 5] -> the stack now consists of [1, 2, 4, 5] and the value popped was 3.
During program execution, the stack will consist of what are known as stack frames. These are frames of data that are pushed onto the stack.